VQA-CE (Counterexamples)
Beyond Question-Based Biases: Assessing Multimodal Shortcut Learning in Visual Question Answering.
This work was published at the ICCV 2021 conference. You can check the paper, and the code.
To download the VQA-CE data, check out our github https://github.com/cdancette/detect-shortcuts
Abstract
We introduce an evaluation methodology for visual question answering (VQA) to better diagnose cases of shortcut learning. These cases happen when a model exploits spurious statistical regularities to produce correct answers but does not actually deploy the desired behavior. There is a need to identify possible shortcuts in a dataset and assess their use before deploying a model in the real world. The research community in VQA has focused exclusively on question-based shortcuts, where a model might, for example, answer “What is the color of the sky” with “blue” by relying mostly on the question-conditional training prior and give little weight to visual evidence. We go a step further and consider multimodal shortcuts that involve both questions and images.

We first identify potential shortcuts in the popular VQA v2 training set by mining trivial predictive rules such as co-occurrences of words and visual elements. We then introduce VQA-CounterExamples (VQA-CE), an evaluation protocol based on our subset of CounterExamples i.e. image-question-answer triplets where our rules lead to incorrect answers. We use this new evaluation in a large-scale study of existing approaches for VQA. We demonstrate that even state-of-the-art models perform poorly and that existing techniques to reduce biases are largely ineffective in this context.
Our findings suggest that past work on question-based biases in VQA has only addressed one facet of a complex issue.
Our VQA-CE (CounterExamples) evaluation protocol
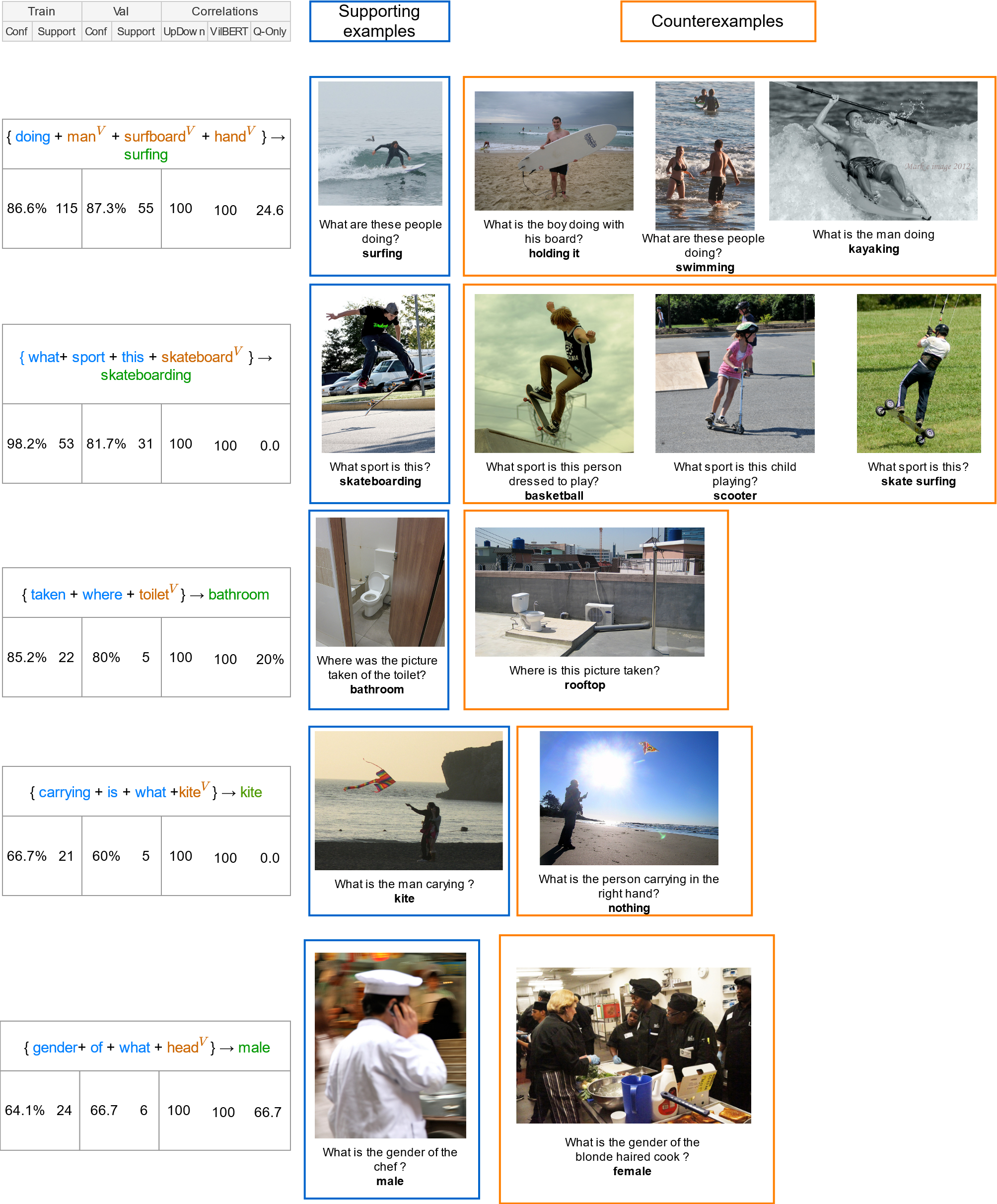
By leveraging the shortcuts that we have detected using our rule mining pipeline , we build the Counterexamples subset of the VQA v2 validation set. This subset is made of 63,298 examples on which all shortcuts provide the incorrect answer. As a consequence, VQA models that exploit these shortcuts to predict will not be able to get accurate answers on this kind of examples. They will be penalized and obtain a lower accuracy on this subset. On the contrary, we build the non-overlapping Easy subset. It is made of 147,681 examples on which at least one shortcut provides the correct answer. On this subset, VQA models that exploit shortcuts can reach high accuracy. Finally, 3,375 examples are not matched by any shortcut’s antecedent.
Results
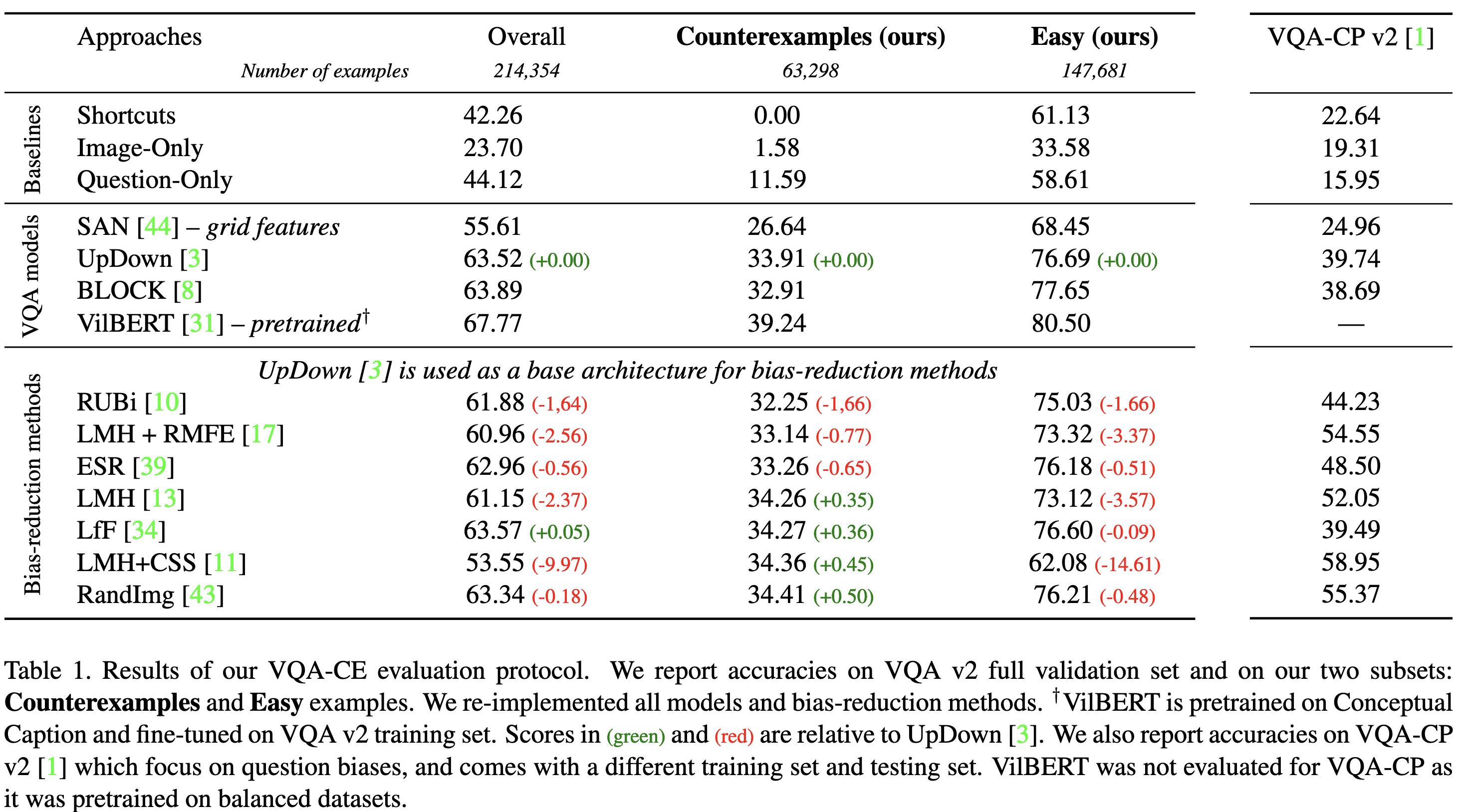
We show that most bias-reduction methods have a very small impact on our counterexamples. It demonstrates the need to build new bias-reduction methods with improved methodology.
Counterexamples