Rubi
Reducing Unimodal Biases for Visual Question Answering.
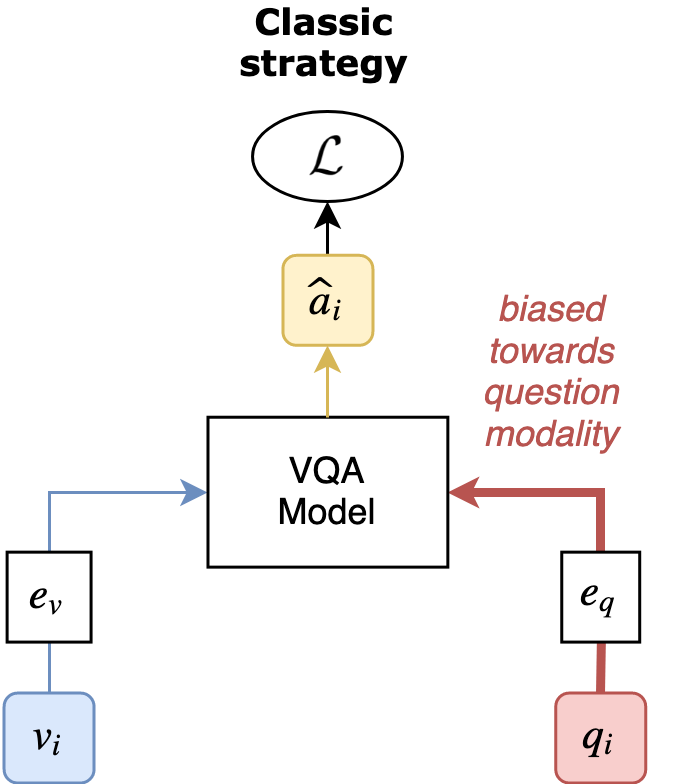
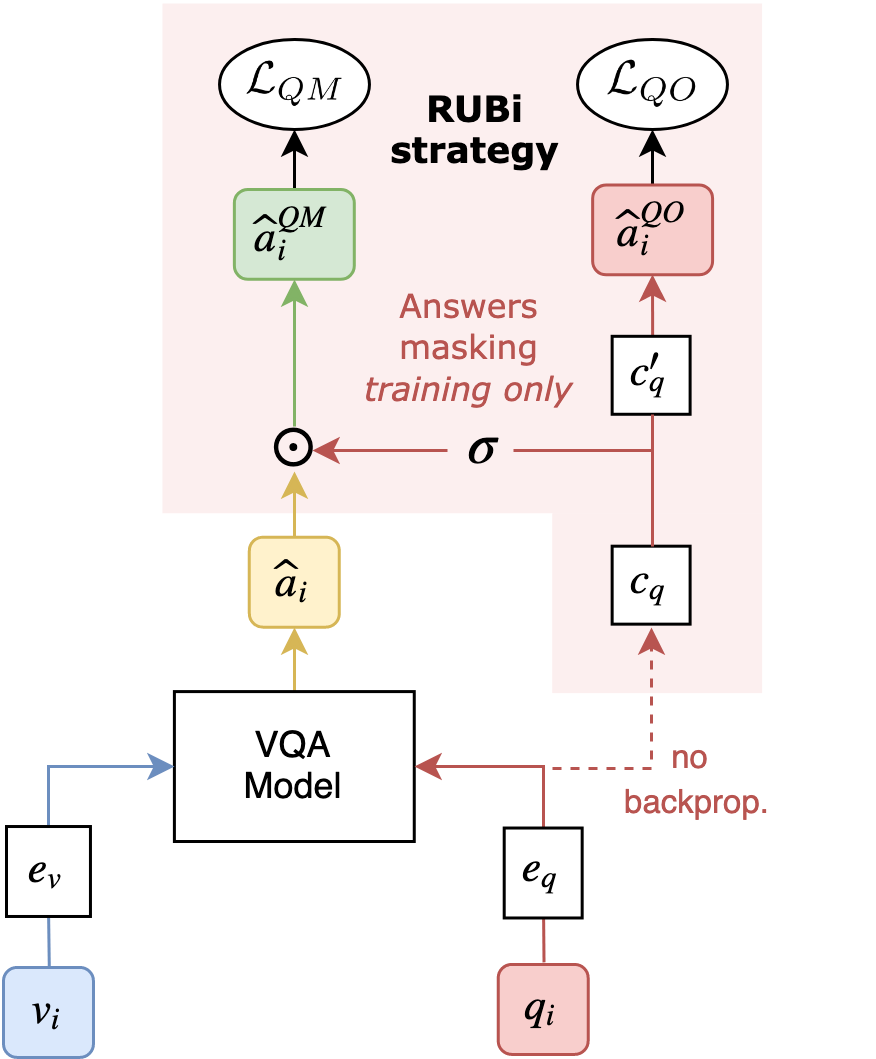
This work was published at the NeurIPS 2019 conference. You can check the paper here, and the code here.
Goals
RUBi is a learning strategy designed to help deep learning models learn a robust behaviour. It helps the models avoid relying on a known source of bias. For Visual Question Answering, the source of bias is the question modality: Models have been shown to rely too much on this input, and too little on the image content.
Method
During training, we merge the prediction of the main VQA model with the prediction of a question-only branch. The question-only branch will predict a 0-1 mask, that will influence the model’s logits. This will encourage the main model to learn less from biased examples (that are answered correctly by the question-only model), and to learn more from examples that the question-only model gets wrong.