-
Augmenting diffusion models with semantic spatial layout conditioning
-
An overview of bias reduction methods for Visual Question Answering
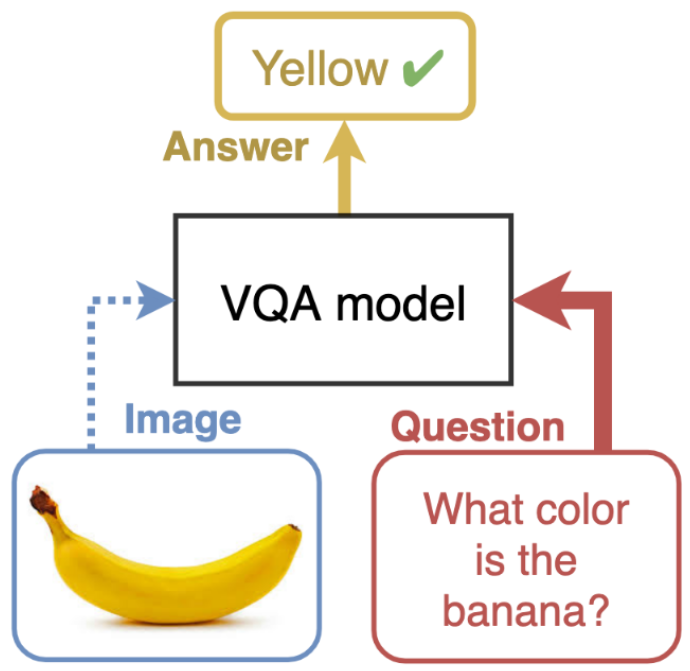
We present various methods designed to reduce biases learned by deep learning models. Most methods will focus on the Visual Answering task, but might be applicable to many other tasks.
-
[Tutoriel] Conduite autonome par imitation grâce à un réseau de convolution (CNN)

Nous allons appliquer un algorithme d’apprentissage supervisé (réseaux de convolution), pour commander la direction d’une voiture dans une simulation 2D: https://gym.openai.com/envs/CarRacing-v0/. Nous allons présenter le fonctionnement d’un réseau de convolution, comment créer le dataset et l’utiliser pour l’entrainement de notre réseau, puis comment utiliser gym pour récupérer la sortie de notre réseau de neurone afin de contrôler la simulation.
-
Why do convolutional neural networks work so well for computer vision ?
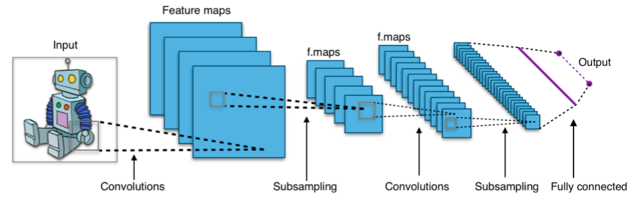
Convolutional neural networks work amazingly well for computer vision tasks, like object detection or segmentation. Where does this power come from ?
-
Reinforcement learning en python sur un jeu simple grâce au Q-learning, Partie 3
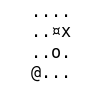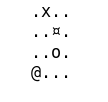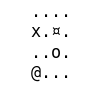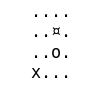
Cet article est la suite de /2017/08/20/reinforcement-learning-part2/.
Dans cette troisième partie, nous allons étudier une variante plus complexe du jeu précédent : le terrain est modifié à chaque partie. Nous n’allons pas pouvoir stocker et visiter tous les états pour entrainer l’agent. Le réseau de neurone apprendra alors a généraliser, pour obtenir une fonction de valeur Q convenable.
-
Fonctionnement d'un réseau de neurone artificiel
Une explication simple sur le principe de fonctionement d’un réseau de neurone, outil de machine learning qui permet d’approximer des fonctions.
-
Reinforcement learning sur un jeu simple grâce au Q-learning, Partie 2 : réseau de neurones avec Keras
Cet article est la suite de /2017/08/18/reinforcement-learning-part1/.
Dans cette deuxième partie, nous allons travailler encore sur le même jeu, mais en utilisant un réseau de neurone au lieu d’un tableau de valeurs.
-
Reinforcement learning en python sur un jeu simple grâce au Q-learning, Partie 1
Un tutoriel pour apprendre le Q-learning sur un jeu simple. Dans cette première partie, on s’interesse au Q-learning stocké dans un tableau de valeurs. Par la suite, on utilisera des reseaux de neurones pour approximer cette table.