Why do convolutional neural networks work so well for computer vision ?
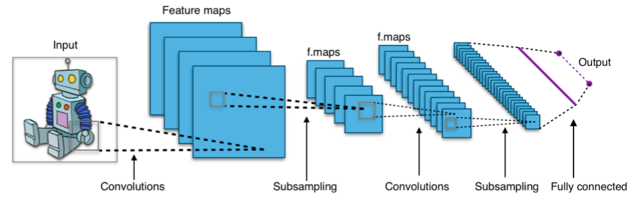
Convolutional neural networks work amazingly well for computer vision tasks, like object detection or segmentation. Where does this power come from ?
What is a convolutional neural network ?
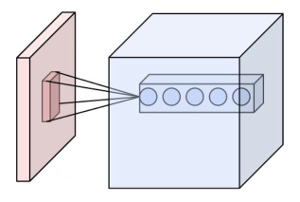
A convolutional neural network (or CNN) is an artificial neural network which has a specific architecture. Instead of having neurons connected to every neuron / input from the precedent layer, neurons are just connected to a few neighbor pixels, in a squared zone. Each neuron is called a filter, and is slid through the image, to each zone. This is called a convolution, hence the name of the network.
You can read the great course http://cs231n.github.io/convolutional-networks/ for more details about CNN.
These networks work amazingly well for computer vision tasks like object detection, or segmentation. I can think of two reasons why they are well suited for this : weight sharing, and image prior.
Weight sharing: Convolutions are much more efficient.
One of the most famous image dataset is ImageNet. It is constituted of more than 1 million images, and the resolution is around 256x256, which is 65536 pixels. Each pixels has 3 colors, which means 196,608 numbers describe an image.
This means that to feed the image to our neural network, if we wanted to use a fully connected network, each neuron would need to have 196,608 weights. And we can guess that to capture any meaningful information about the image, the network will need many neurons, and many layers. If we have 10,000 neurons on the first layer, that’s more than 10 billion weights, that will all need to be updated at each iteration. This makes things totally impracticable, even with our best GPU.
Convolutional neural network, thanks to their architecture, and the weight sharing between convolutions, have much less connexions.
For example, one of the most famous neural network, AlexNet, has about 650,000 neurons, and 60 million weights. It has about 300,000 neurons just for the first layer. With a fully connected network, this would be impossible.
This makes our network much faster to train than fully connected neural networks with the same number of neurons, and it doesn’t impact their representation potential. It is a great power.
Its architecture captures the image distribution space
Its architecture is a great prior to capture an inductive bias of images that fully connected networks don’t : Images are a 2D structure, and pixels have neighbors, which are very related to them. Thus it is very useful to compare pixels in a small zone, but much less to compare two random pixels of an image.
CNN uses convolutions, which are local operations, which act on neighbor pixels. And patterns on images are also local : if you want to detect a line on the image, you need to see if there is a continuous pattern of pixels of the same color, bordered by a different color.
A great paper that uses this idea is Deep Image Prior : It uses convolutional neural networks without training on a dataset, to reconstruct corrupted images in a very impressive manner. The neural network reconstructs the image by minimizing the distance between the wanted image and the output of the network, for a fixed input. It only needs the corrupted image, and doesn’t need training before.
The idea is that the corrupted image needs more information than the original image for its encoding (the corruption adds information), and the neural network, if we stop training fast enough (if we let training for too long, the network will overfit the corrupted information). In this experiment, the force of the neural networks comes only from its architecture, and has nothing to do with the backpropagation algorithm, which is often seen as the reason why neural networks are so performant.