Reinforcement learning en python sur un jeu simple grâce au Q-learning, Partie 3
Cet article est la suite de /2017/08/20/reinforcement-learning-part2/.
Dans cette troisième partie, nous allons étudier une variante plus complexe du jeu précédent : le terrain est modifié à chaque partie. Nous n’allons pas pouvoir stocker et visiter tous les états pour entrainer l’agent. Le réseau de neurone apprendra alors a généraliser, pour obtenir une fonction de valeur Q convenable.
Tous les codes présentés ici peuvent être trouvés sur github.
Plan
- Partie 1 : jeu statique, le terrain ne change pas, utilisation d’un tableau de valeurs (sans réseau de neurones).
- Partie 2 : Jeu statique, le terrain ne change pas, utilisation d’un réseau de neurone pour approximer la fonction de valeurs Q.
- Partie 3 : Jeu dynamique, le terrain change à chaque partie : utilisation d’un réseau de neurones.
Le jeu
Le jeu est identique aux versions précédentes. Une seule différence : nous allons regénérer un terrain à chaque nouvelle partie. Ainsi Le seul changement sera la manière d’encoder l’état du jeu.
Ainsi, la fonction get_state sera réécrite de la manière suivante :
def _get_state(self):
x, y = self.position
if self.alea:
return np.reshape([self._get_grille(x, y) for (x, y) in
[self.position, self.end, self.hole, self.block]], (1, 64))
return flatten(self._get_grille(x, y))Ici, au lieu de renvoyer un tableau de taille 16 contenant juste la position de notre agent marqué par un 1, nous devons également indiquer la position des éléments sur le terrain.
Les éléments à indiquer sont : notre position self.position, la position de l’arrivée self.end, la position du trou self.hole, et la position du mur self.block.
Au lieu d’un tableau de taille 16 contenant des 0, avec un 1 pour marquer la position de l’agent, nous avons maintenant 4 tableaux similaires. L’état du jeu sera la concaténation de ces 4 tableaux (obtenu avec np.reshape).
L’état est donc un tableau de taille 4x16 = 64 cases, et il contiendra quatre 1, et les autres éléments seront des 0.
Ici pour encoder les états, nous avons utilisé ce qui est appelé un One Hot encoder : Pour chaque élément, il y a 16 possibilités, et on encode cela en utilisant un tableau de 16 cases, en mettant un 1 pour représenter la position de l’élément, et 0 dans les autres cases. Ce n’est pas une représentation très compacte : les 16 cases possibles peuvent être encodées sur 4 bits, il nous suffirait donc de 4 cases dans notre tableau pour encoder la position de chaque élément. Mais le réseau devrait alors apprendre à décoder cette représentation, ce qui nécessiterait certainement un modèle plus complexe, donc un entrainement plus long, ou bien une architecture plus grosse. L’encodage que nous avons choisi ici est extrèmement simple (mais il n’est pas le plus compact possible, toutes les entrées possibles ne sont pas du tout utilisés), et sera utilisé très facilement par le réseau de neurone.
Un problème plus complexe
On peut voir que le problème est plus complexe que celui de la partie précédente : au lieu de 4 états différents, encodés dans un tableau de taille 16, on a 16x15x14x13 = 43680 états possibles. Il serait difficile d’appliquer la méthode de la première partie de ce tutoriel (stocker les Q-values dans un tableau). L’utilisation d’un réseau de neurone, comme nous l’avons vu dans la partie 2, nous sera alors très utile ici. Avec un réseau légèrement plus complexe, nous allons pouvoir résoudre ce problème. Néanmoins, l’entrainement est plus compliqué ici. Pour garantir la convergence de la méthode classique du Q-learning, l’agent devrait parcourir tous les états un grand nombre de fois. Or ici, notre espace d’état étant très grand, l’agent ne parcourera surement pas la totalité de ces états de nombreuses fois. C’est pour cela que nous attendons de notre réseau de neurone qu’il généralise, pour appliquer ses connaissances acquises à l’entrainement sur des états qu’il n’a jamais rencontré. Il aurait été impossible de généraliser avec la méthode de l’article 1, en utilisant un tableau.
Nous allons évoquer plusieurs concepts très utilisés en machine learning et en reinforcement learning : le principe du batch, et celui de l’experience replay.
Batch
En machine learning, pour entrainer nos réseaux de neurones, on utilise généralement des batch de données. C’est à dire qu’au lieu de ne donner qu’un seul exemple, avec son label, on lui donne à chaque fois un nombre fixe d’exemples (par exemple 10 samples). Cela permet à l’algorithme de gradient de choisir une direction qui ne dépendra pas que d’un seul exemple, qui pourrait être trop précis et ne pas améliorer le score global, mais plutôt une direction moyenne, qui sera certainement plus bénéfique au réseau de manière générale.
Le batching est également utilisé quand le dataset entier ne rentre pas dans la RAM / la mémoire du GPU. Il est alors nécéssaire de diviser le dataset en batches, que l’on va charger en mémoire pour entrainer le réseau, puis décharger. La contrainte est alors que la taille d’un batch ne dépasse pas la taille de la mémoire (c’est surtout un problème en traitement d’image, ou les données ont une taille importante).
Le batching est utilisé avec l’algorithme de stochastig gradient descent ou descente de gradiant stochastique, en remplaçant un exemple par un petit nombre d’exemples (ou bien avec d’autres algorithmes dérivés tels que Adam).
Le batching est très souvent utilisé en deep learning. Toutefois en reinforcement learning, cela paraît plus compliqué, puisque nous n’avons qu’un exemple à chaque action effectuée. Il est donc impossible à priori d’utiliser cette méthode. Nous allons voir que la méthode de l’experience replay permet de résoudre ce problème
Experience Replay
L’experience replay est une méthode spécifique au reinforcement learning (contrairement au batching qui est utilisé très souvent en deep learning).
Il nous permet en fait d’utiliser des batch pendant l’entrainement de notre agent, au lieu de l’entrainer à chaque mouvement sur les données qu’il vient de recevoir.
Il s’agit de stocker à chaque mouvement les paramètres d’entrainement (état de départ, action, état d’arrivée, récompense, fin du jeu) dans une mémoire, au lieu d’entrainer notre réseau de neurone dessus. Et ensuite, régulièrement, on va piocher un batch dans cette mémoire (c’est à dire un certain nombre d’exemples), au hasard, et on va entrainer notre réseau sur ce batch.
Cela permet d’éviter un trop grand va-et-vient des poids du réseau. En effet, le réseau oublie ce qu’il vient d’apprendre si on lui donne des exemples successifs qui ont des indications contraires (il n’arrive pas à généraliser, et va osciller). En lui donnant un batch en effet, la backpropagation va choisir une direction moyenne pour optimiser les poids du réseau afin de faire diminuer l’erreur.
Cela va également nous permettre de voir plusieurs fois des situations passées. Et les exemples trop vieux seront vidés de la mémoire (on limite la taille de la mémoire en nombre d’exemples).
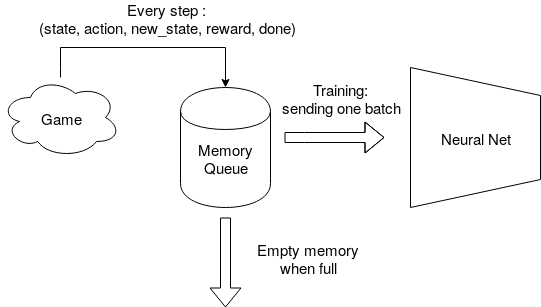
Il existe de nombreuses améliorations possibles. Par exempe, le *Prioritized experience replay (article [1] ou blog), ou on voit les situations les plus importantes en priorité, au lieu tirer des exemples au hasard dans la mémoire.
Code
Paramètres du trainer
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import RMSprop, Adam, sgd
from keras.layers.advanced_activations import LeakyReLU
import random
class Trainer:
def __init__(self, name=None, learning_rate=0.001, epsilon_decay=0.9999, batch_size=30, memory_size=3000):
self.state_size = 64
self.action_size = 4
self.gamma = 0.9
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = epsilon_decay
self.learning_rate = learning_rate
self.memory = deque(maxlen=memory_size)
self.batch_size = batch_size
self.name = name
if name is not None and os.path.isfile("model-" + name):
model = load_model("model-" + name)
else:
model = Sequential()
model.add(Dense(50, input_dim=self.state_size, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
self.model = modelLes paramètres sont assez similaires à ceux de l’article p’écédent. On a juste ajouté une nouvelle couche à notre réseau (pour lui donner une meilleur force de représentation des données).
La ligne qui change est celle-ci :
self.memory = deque(maxlen=memory_size)memory est la structure de données qui va nous servir de mémoire pour stocker nos ensembles (state, action, new_state, reward). C’est grâce à cette mémoire que l’on peut faire de l’experience replay. A chaque action, on va remplir cette mémoire au lieu d’entrainer, puis on va régulièrement piocher aléatoirement des samples dans cette mémoire, pour lancer l’entrainement sur un batch de données.
Pour stocker, on utilise la structure collections.deque de python. Il s’agit d’une queue qui peut avoir une taille limitée, qui va supprimer automatiquement les éléments ajoutés les premiers lorsque la taille limite est atteinte.
Apprentissage
Nous allons remplacer la fonction train par une fonction remember Au lieu de lancer une étape de backpropagation, elle va tout simplement stocker ce que l’on vient de voir, dans une queue (une structure de données qui va supprimer les éléments entrés en premier).
class Trainer:
...
def remember(self, state, action, reward, next_state, done):
self.memory.append([state, action, reward, next_state, done])
Et enfin, il nous faut une fonction replay qui va piocher dans la mémoire, et donner ces données aux réseau de neurone.
def replay(self, batch_size):
batch_size = min(batch_size, len(self.memory))
minibatch = random.sample(self.memory, batch_size)
inputs = np.zeros((batch_size, self.state_size))
outputs = np.zeros((batch_size, self.action_size))
for i, (state, action, reward, next_state, done) in enumerate(minibatch):
target = self.model.predict(state)[0]
if done:
target[action] = reward
else:
target[action] = reward + self.gamma * np.max(self.model.predict(next_state))
inputs[i] = state
outputs[i] = targetAinsi, ici, on va utiliser random.sample pour piocher un certain nombres d’éléments aléatoirement dans la mémoire.
On crée alors nos entrées et sorties dans le bon format pour le réseau de neurone, similairement à la fonction train de l’article précédent. La différence est qu’ici, on crée un batch de plusieurs samples, au lieu de n’en donner qu’un (on voit que la dimension des input et output est (batch_size, state_size), alors qu’elle n’avait qu’une dimension précedemment.
Récapitulatif du code du trainer
# defining the neural network
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import RMSprop, Adam, sgd
from keras.layers.advanced_activations import LeakyReLU
import random
from collections import deque
class Trainer:
def __init__(self, name=None, learning_rate=0.001, epsilon_decay=0.9999, batch_size=30, memory_size=3000):
self.state_size = 64
self.action_size = 4
self.gamma = 0.9
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = epsilon_decay
self.learning_rate = learning_rate
self.memory = deque(maxlen=memory_size)
self.batch_size = batch_size
self.name = name
if name is not None and os.path.isfile("model-" + name):
model = load_model("model-" + name)
else:
model = Sequential()
model.add(Dense(50, input_dim=self.state_size, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
self.model = model
def decay_epsilon(self):
self.epsilon *= self.epsilon_decay
def get_best_action(self, state, rand=True):
if rand and np.random.rand() <= self.epsilon:
# The agent acts randomly
return random.randrange(self.action_size)
# Predict the reward value based on the given state
act_values = self.model.predict(np.array(state))
# Pick the action based on the predicted reward
action = np.argmax(act_values[0])
return action
def remember(self, state, action, reward, next_state, done):
self.memory.append([state, action, reward, next_state, done])
def replay(self, batch_size):
batch_size = min(batch_size, len(self.memory))
minibatch = random.sample(self.memory, batch_size)
inputs = np.zeros((batch_size, self.state_size))
outputs = np.zeros((batch_size, self.action_size))
for i, (state, action, reward, next_state, done) in enumerate(minibatch):
target = self.model.predict(state)[0]
if done:
target[action] = reward
else:
target[action] = reward + self.gamma * np.max(self.model.predict(next_state))
inputs[i] = state
outputs[i] = target
return self.model.fit(inputs, outputs, epochs=1, verbose=0, batch_size=batch_size)
def save(self, id=None, overwrite=False):
name = 'model'
if self.name:
name += '-' + self.name
else:
name += '-' + str(time.time())
if id:
name += '-' + id
self.model.save(name, overwrite=overwrite)Lancer l’entrainement
La fonction d’entrainement est un peu plus complexe, puisqu’on va executer une première partie ou l’on va remplir en partie la mémoire. Cela nous permettra de pouvoir créer des batch avec assez de données plus rapidement. Cette phase se déroule entre les lignes 13 et 25 du code ci-dessous.
La deuxième phase est l’entrainement du réseau. On lance un entrainement à chaque 100 mouvements. On pourrait essayer d’en lancer plus ou moins souvent, l’apprentissage en serait surement impacté au niveau rapidité de convergence et qualité du minimum local. En général, lorsqu’un algorithme converge trop vite, le minimum local sera moins bon.
import time
def train(episodes, trainer, wrong_action_p, alea, collecting=False, snapshot=5000):
batch_size = 32
g = Game(4, 4, wrong_action_p, alea=alea)
counter = 1
scores = []
global_counter = 0
losses = [0]
epsilons = []
# we start with a sequence to collect information, without learning
if collecting:
collecting_steps = 10000
print("Collecting game without learning")
steps = 0
while steps < collecting_steps:
state = g.reset()
done = False
while not done:
steps += 1
action = g.get_random_action()
next_state, reward, done, _ = g.move(action)
trainer.remember(state, action, reward, next_state, done)
state = next_state
print("Starting training")
global_counter = 0
for e in range(episodes+1):
state = g.generate_game()
state = np.reshape(state, [1, 64])
score = 0
done = False
steps = 0
while not done:
steps += 1
global_counter += 1
action = trainer.get_best_action(state)
trainer.decay_epsilon()
next_state, reward, done, _ = g.move(action)
next_state = np.reshape(next_state, [1, 64])
score += reward
trainer.remember(state, action, reward, next_state, done) # ici on enregistre le sample dans la mémoire
state = next_state
if global_counter % 100 == 0:
l = trainer.replay(batch_size) # ici on lance le 'replay', c'est un entrainement du réseau
losses.append(l.history['loss'][0])
if done:
scores.append(score)
epsilons.append(trainer.epsilon)
if steps > 200:
break
if e % 200 == 0:
print("episode: {}/{}, moves: {}, score: {}, epsilon: {}, loss: {}"
.format(e, episodes, steps, score, trainer.epsilon, losses[-1]))
if e > 0 and e % snapshot == 0:
trainer.save(id='iteration-%s' % e)
return scores, losses, epsilonsOn peut alors lancer l’entrainement
trainer = Trainer(learning_rate=0.001, epsilon_decay=0.999995)
scores, losses, epsilons = train(35000, trainer, 0.1, True, snapshot=2500)
> Starting training
> episode: 0/35000, moves: 2, score: 9, epsilon: 0.9999900000249999, loss: 0
> episode: 200/35000, moves: 3, score: -12, epsilon: 0.9822592094161423, loss: 2.4857234954833984
> episode: 400/35000, moves: 35, score: -44, epsilon: 0.9650068405161227, loss: 1.1590536832809448
> episode: 600/35000, moves: 11, score: -20, epsilon: 0.9500077578972453, loss: 0.09752733260393143
...
Puis affichons les courbes de loss
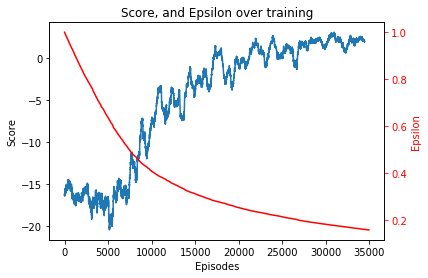
On voit très clairement que notre réseau a appris à jouer de manière satisfaisante. Le score moyen en fin d’apprentissage est légèrement au dessus de 0, ce qui veut dire que l’agent arrive à la fin en moyenne en moins de 10 coups.
Quelques parties intéressantes
Plusieurs parties assez simples


Et celle-ci ou l’agent fait plusieurs erreurs mais arrive eventuellement à la fin
Si vous avez aimé cet article, n’hésitez pas à m’envoyer un mail.
Resources (en anglais)
- [1] Prioritized Experience Replay, Tom Schaul, John Quan, Ioannis Antonoglou and David Silver, Google DeepMind
- http://neuro.cs.ut.ee/demystifying-deep-reinforcement-learning/
- http://outlace.com/rlpart3.html
- https://mpatacchiola.github.io/blog/2016/12/09/dissecting-reinforcement-learning.html
- https://medium.com/@awjuliani/super-simple-reinforcement-learning-tutorial-part-1-fd544fab149