Zero Resource Challenge: Unsupervised subword modeling with a Variational Auto Encoder
Corentin DancetteFall 2018 CS 4803 / 7643 Deep Learning: Class Project
Georgia Tech
Abstract
The goal Zero Resource Speech Challenge[1] is to build speech systems in an unsupervised manner, meaning without textual annotations. The first part of the challenge is unsupervised learning of speech embedding: Constructing embedding for every chunk of the audio signal, that will represent the phonetic content of this audio chunk, and will be independant of the speaker. In this work, I present the a Variational Auto Encoder based architecture for learning those speech embeddings. The results I obtained didn't reach state of the art for neural network based architectures, but results are encouraging for the use of VAE in this context.
The code for the experiments is available here: https://github.com/cdancette/zerospeech-vae. The pytorch framework was used for this work.
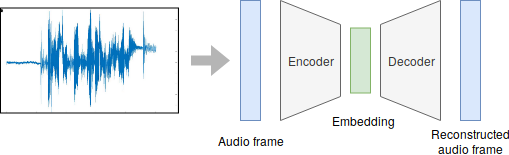
Introduction / Background / Motivation
What did you try to do? What problem did you try to solve? Articulate your objectives using absolutely no jargon.
Learning invariant speech representations is a current research topic. For each frame of the audio input, we learn to build an embedding (vector representation), that will be dependant on the input's phoneme, and independant of the the other speech properties (such as the speaker, and the prosody). This enables us to build better speech recognition systems, if we can recognize every phoneme, we can deduce the letter that was used at this moment, and deduce which word was used by assembling those letters.
The main approach for this is supervised learning: use huge datasets composed of both audio and text, and train a speech to text pipeline.
We can then extract some speech embedding if we need it, similarly to computer vision.
Here, we adress the problem of learning representations with very small or inexistant textual resources. This can be useful for languages with no alphabet, or languages with very little speakers, where it is expensive to annotate recordings. Also, this is how new borns learn language: they don't use textual input, only the raw audio. We want to reproduce this behaviour.
In this work, I tried to use a Variational Auto Encoder to build those embeddings of speech signal. This model seems very appropriate here, as it gives us directly an internal compressed representation of the input signal.
This is a continuation of the work I did on the zerospeech challenge, as a research intern in the Cognitive Machine Learning team [3].
How is it done today, and what are the limits of current practice?
The current best architecture for unsupervised learinng of speech embeddings is based on gaussian mixture models, and clustering [1]. An other common approach is to train a Siamese Neural Network with pairs of similar and dissimilar words as input [2, 3]. Siamese are trained by recieving pairs of similar or dissimilar inputs (ie contain the same phonemes, or different phonemes), and must learn to create an embedding that is the same, or different. Those pairs can be constructed from a lexicon discovered with an unsupervised Spoken Term Discovery algorithm (which is the Track 2 of the Zero Resource challenge). This is a case of semi-supervised learning.The current approaches are very far from the success rates of supervised methods.
Who cares? If you are successful, what difference will it make?
It will be very useful for languages which don't have massive resources available. On those "low-level" languages, unsupervised learning can help build speech recognition pipelines. It can also be used to preserve disappearing languages, and help linguists annotate those languages before they disappear. Finally, it can be considered as a predictive model of infant language learning.Approach
What did you do exactly? How did you solve the problem? Why did you think it would be successful? Is anything new in your approach?
Feature Preparation
The raw audio signal is a 1D vector, whose length is the duration of the signal times the sampling rate. We cannot use directly this 1D vector, as neural networks have a hard time understanding this representation. What is usually done is convert this 1D signal to a spectrum, using fourier transform. We call these features **filter banks**. Similarly to [2, 3], in our experiments, the raw audio signal is converted to 40 frequency bands, with a window length of 25 ms, and a stride of 10ms (meaning we have an overlap between two consecutive features). The package provided in abnet3 repository was used to preprocess the raw audio signal to those filter banks features. This package is a siamese neural network developed in the CoML team, for the same task we are adressing here (zero resource speech challenge, track 1).
After extracting the signal, we stack the features 7 by 7 (with a stride of 1). This means each feature gets stacked with the 3 frames before it and the 7 frames after it). Each frame is spaced by 10ms, this means that we will range over about 70ms of signal, which is the lower bound for the duration of a phoneme (they usually range between 50 and 200ms). This means we will certainly have a few frames that will encode the same phoneme. This stacking is the same used by [2, 3]. Using only one frame was shown to be not sufficient to learn speech representations.
Finally, for training, I splitted the training data set into a train set and a validation set. We still have a testing set, that is separate, and is used for evaluation of the final embeddings. The testing set is also provided by the challenge, so we don't need to split it from our data. For the train / validation split, I splitted the audio files into two groups, to get different speakers in the two groups. This avoids overfitting on the speakers of the training set, as the speakers in the final testing set are also differents.
Auto Encoder, loss
Now, we can feed those filter banks to the neural network. Here, as a model, we use a Variational Auto Encoder. This model, to this date, hasn't been tested in a published paper for the zero resource challenge, so it is a new approach. My code is based on the example provided in the pytorch code, but was widely modified to fit the needs of this work. The setup is simple: feed the filter banks as an input to the variational auto encoder, and train it to create an embedding of smaller size. Then, we can evaluate the embedding using the package provided by the zero speech challenge: https://github.com/bootphon/zerospeech2017.
We need to choose a large number of hyperparameters : the loss we use, the architecture of the VAE, optimiser parameters... I describe in the Experiments section the choices I made, and the parameters I compared.
What problems did you anticipate? What problems did you encounter? Did the very first thing you tried work?
The zerospeech track 1 is a hard problem, I didn't expect to get state of the art results with the first thing I tried. I hoped to match the results obtained by other neural network approaches, or at least provide a new comparison point for the followning research that will try to use VAE or other neural network based models for this problem.
The main problem I expected was to separate the phonetic information and the speaker / prosody information. My hope was that the autoencoder would provide features in which every dimension was independant of the others, in which we could separate speaker information and phonetic information. The variational auto encoder is known to provide such representations.
A thing we could then do is use a dimensionality reduction algorithm to get rid of the dimensions that don't vary much within speakers, but that vary much across speakers. I didn't get the time to try this, but it could be an interesting thing to try.
I also encountered an overfitting problem, as we will ses below in the training curves, which made me test only small architectures. It would be better to use regularization methods here, that would allow to use more powerfull architectures.
Experiments and Results
The zerospeech challenge has three training languages and two surprise testing languages. Due to the limitied time available for this project, I trained the autoencoder on only one of the training languages, the mandarin. It is the smallest corpus, which allows for quick training and testing. Being quite small, it can although be a problem, as neural networks tend to need a large amount of training data to train well, and are subject to overfitting.
How did you measure success? What experiments were used? What were the results, both quantitative and qualitative? Did you succeed? Did you fail? Why?
ABX error
The challenge comes with an evaluation software that measures the quality of the embeddings provided. It measures the ability of the embeddings to discriminate phonemes between them. The score is the ABX discriminate, and is measured as an error rate (lower error is better) [4]. It consists in comparing triplets of phoneme embeddings, called A, B and X, and to ask if X is closer to A or to B. If our embeddings are able to get the right answer, they have a good discriminability for triplet A, B and X. Taking the average over an entier dataset of triplets gives us the ABX score.
My experiments
I tried to experiment three parameters: The loss (binary cross entropy or mean squared error), the embedding size (in siamese network works, an embedding size of 100 is used, so I started with this number), and compared with an embedding size of 50. The average number of phonemes is around 50, so this seems like a good lower bound for or embedding size (see https://en.wikipedia.org/wiki/Phoneme#Numbers_of_phonemes_in_different_languages). I fixed the hidden layers size to 400, this would be another parameter to tweak.
The last parameter I played with was then number of hidden layers. I tried 1 and 2, as overfitting started to happen with 2 layers. It would be good to test mode regularization techniques, to be able to increase the model size. This problem also might not happen with other languages of the zerospeech challenge, as their datasets are much bigger.
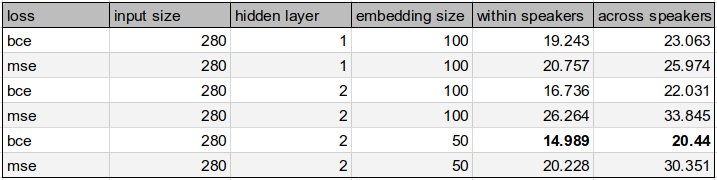
Table of results. The last two columns are the ABX error rates with and across speakers.
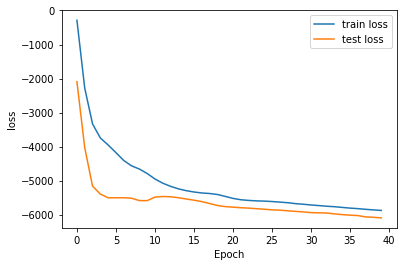
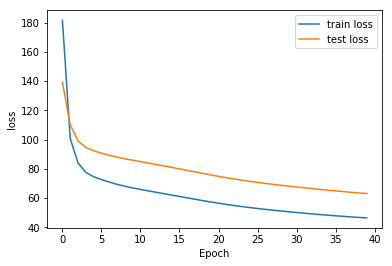
The respective training curves for those experiments are the following:
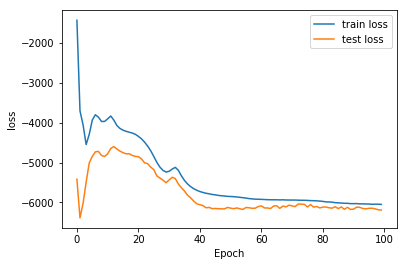
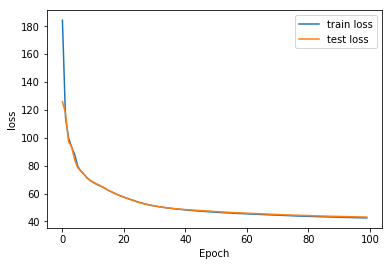
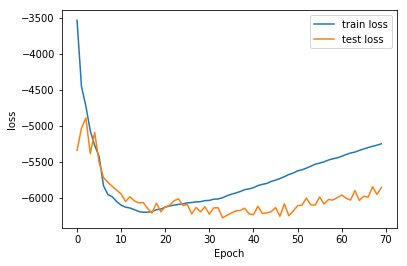
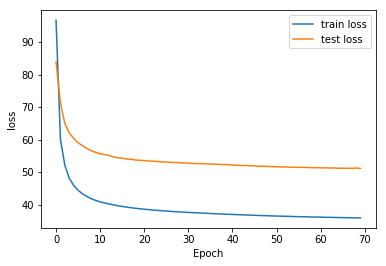
Number of hidden layers
First, we can compare the number of layers, with the embedding size of 100 fixed:
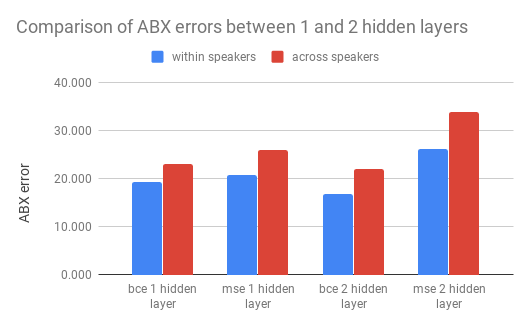
The first thing we can notice is that the within speaker is always lower than the across speakers. This is expected, because it is harder to discriminate between phonemes of two different speakers than to discriminate phonemes from the same speaker. In the within speakers, the three phonemes A, B and X are from the same speaker s. In the across speaker, X is from a different speaker as A and B.
Nothing unexpected here.
The next thing we can notice is that for a given hidden layer size, binary cross entropy loss always outperforms mean squared error loss. This is a common result for variational auto encoder. This can work because we normalized our inputs to be in the 0-1 range, and the output goes through a sigmoid layer (for the BCE loss only).
Finally, we can notice that the 2-hidden layers networks outperform the 1-hidden layer networks for binary cross entropy, but becomes actually worse for mean squared error loss. This is a weird behaviour, which we might want to explore more.
Overall, the best results comes with binary cross entropy, with 2 hidden layers.
Size of embeddings
Now, we can compare the ABX error for various embedding sizes, with a fixed 2-hidden layers.
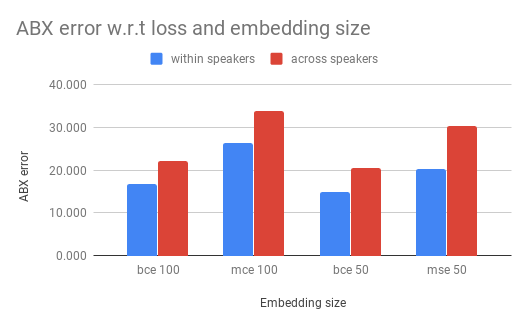
We see that BCE is still better than MSE here, no surprises.
What is surprising is that an embedding size of 50 gives actually better results than the embedding size of 100. This could be explained by the lack of training data: an embedding of size 100 could overfit more quickly our dataset. A smaller embedding could act like a regularization. More experiments are needed to this hypothesis.
Best result overall
As we can see in the table above, or in the graphs, the best result overall was reached with binary cross entropy loss, 2 hidden layers, and an embedding size of 50. The results for the ABX errors are: 14.99% within speakers, and 20.44% across speakers.
Comparison with state of the art results
The results for the zerospeech challenge are available at http://sapience.dec.ens.fr/bootphon/2017/page_5.html.
Here is the comparison with the baseline (MFCC) and with the best unsupervised results (based on gaussian mixture models).
| Method | ABX within | ABX across |
|---|---|---|
| Ours | 14.99 | 20.44 |
| Baseline MFCC | 11.5 | 21.3 |
| Chen et al. Northwestern Polytechnical University | 8.5 | 10.8 |
We are still far from the best unsupervised result. A encouraging result is that we beat the baseline for across-speakers ABX error. With more experiments, we could certainly bring those results under the baseline for both within and across speakers.
Conclusion and Future work
This work opens many questions, that would need further experiments. The first one is to try more architectures and hyperparameters. Only a few parameters were tested here, due to the limited time available for this project.
Regularization methods should also help here, as we see that overfitting is happening in our training curves, in some cases. This would then allow us to use bigger networks, and certainly get better generalization.
Also, as discussed previously, the VAE here is not explicitely trained to extract only phonetic information from the audio. It will extract all the information it can to reconstruct the original audio signal. It would be good to check that the dimensions of the embeddings are independant, and check if some of them describe the speaker properties, and some the phonetic properties of the input signal. We could then try to get rid of the speaker-related dimensions and keep only the ones we care about, using a dimensionality reduction algorithm like PCA.
Another idea would be to add a recurrent layer in the architecture. Speech is a sequential data, unlike image, so adding recurrence could help us build better embeddings.
References
[1] Dunbar, E., Cao, X., Benjumea, J., Karadayi, J., Bernard, M., Besacier, L., Miró, X.A., & Dupoux, E. (2015). The zero resource speech challenge 2017. 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 323-330.
[2] Synnaeve, G., Schatz, T., & Dupoux, E. (2014). Phonetics embedding learning with side information. 2014 IEEE Spoken Language Technology Workshop (SLT), 106-111.
[3] Riad, R., Dancette, C., Karadayi, J., Zeghidour, N., Schatz, T., & Dupoux, E. (2018). Sampling Strategies in Siamese Networks for Unsupervised Speech Representation Learning. Interspeech 2018.
[4] Schatz, V. Peddinti, F. Bach, A. Jansen, H. Hermansky, and E. Dupoux, “Evaluating speech features with the minimal-pair abx task: Analysis of the classical mfc/plp pipeline,” in INTERSPEECH 2013: 14th Annual Conference of the International Speech Communication Association, 2013, pp. 1–5.